因为公司部署的Spark集群版本还停留在1.5.2,但现在spark已经更新到2.0.1了。由于想迫切尝试下spark的新特性,如Spark ML模型保存功能,SparkSession统一接口 etc. 因此想到是否可以基于现有的集群环境来运行最新版本spark程序,经过几番捣腾,终于成功,固记录下来分享给大家。
本文使用的spark版本是2.0.0,而公司的集群spark版本是1.5.2
1. 首先去官网http://spark.apache.org/下载最新版本包,也可去github上clone最新源码,然后在IDEA中编译
step1 由于spark2.0取消了spark-assembly jar,但2.0之前打包方式均为assembly jar形式;如果还想使用assembly jar形式,可以修改源码assembly模块中pom.xml配置:
|
|
step2 spark解压后目录:
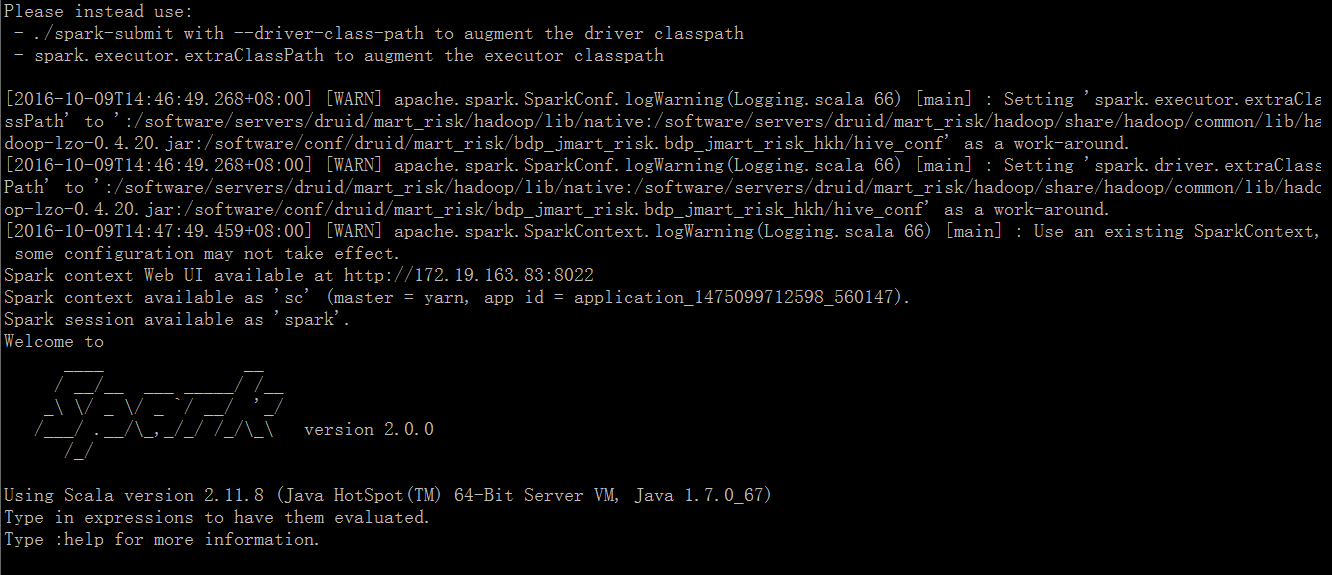
2. 因spark-shell,spark-sql,spark-submit运行时需要读取SPARK_HOME与SPARK_CONF_DIR配置,为让spark不用原生产环境中的配置,所以需要重新设置零时环境变量(对当前会话窗口有效)
3. 修改conf/spark-defaults.conf文件,避免让spark运行时读取系统原有配置文件
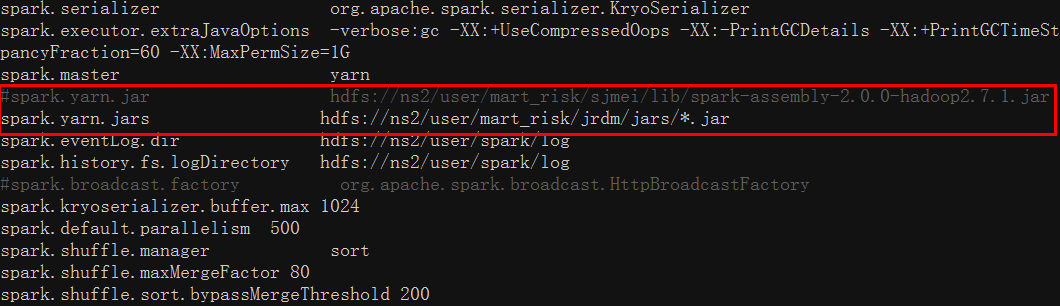
4. 经过上述同步,spark2.0就设置好了,接下来就可以试试运行bin/spark-shell,bin/spark-submit来提交任务了^_^